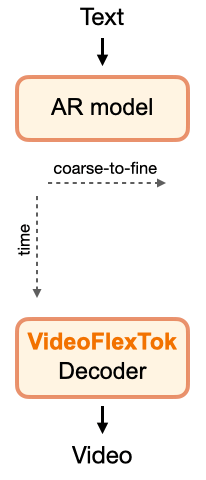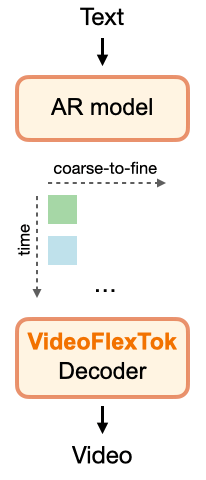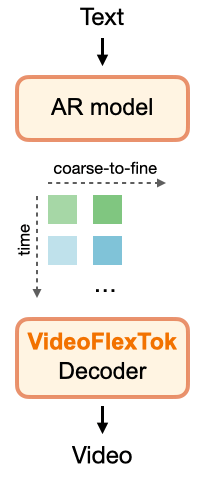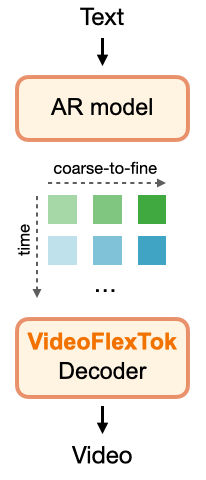
VideoFlexTok method overview
We design our VideoFlexTok tokenizer to have the following three main properties:- Flexible-length tokenization: The encoder produces a variable-length sequence of tokens. This allows the downstream models to adapt the token count based on task requirements. Following FlexTok, we achieve this by applying nested dropout over the register tokens.
- Coarse-to-fine semantic ordering: Earlier tokens capture higher-level semantic information, while later tokens encode finer details. We achieve this by using DINOv2 self-supervised features as an auxiliary target during training.
- High-fidelity reconstruction: The decoder reconstructs plausible realistic videos from any number of tokens, preserving information captured by the tokens. We achieve this by using a generative flow decoder conditioned on the encoded tokens, which also provides a reconstruction objective for encoder training.

VideoFlexTok: The ViT encoder with registers resamples 3D video VAE latents to a temporal coarse-to-fine sequence of tokens. Nested dropout is applied over the register tokens to promote the coarse-to-fine structure. Combined with a semantic bias in the form of REPA loss predicting DINOv2 features leads to early tokens capturing the most salient semantic information. A generative flow decoder reconstructs realistic videos from any number of tokens.
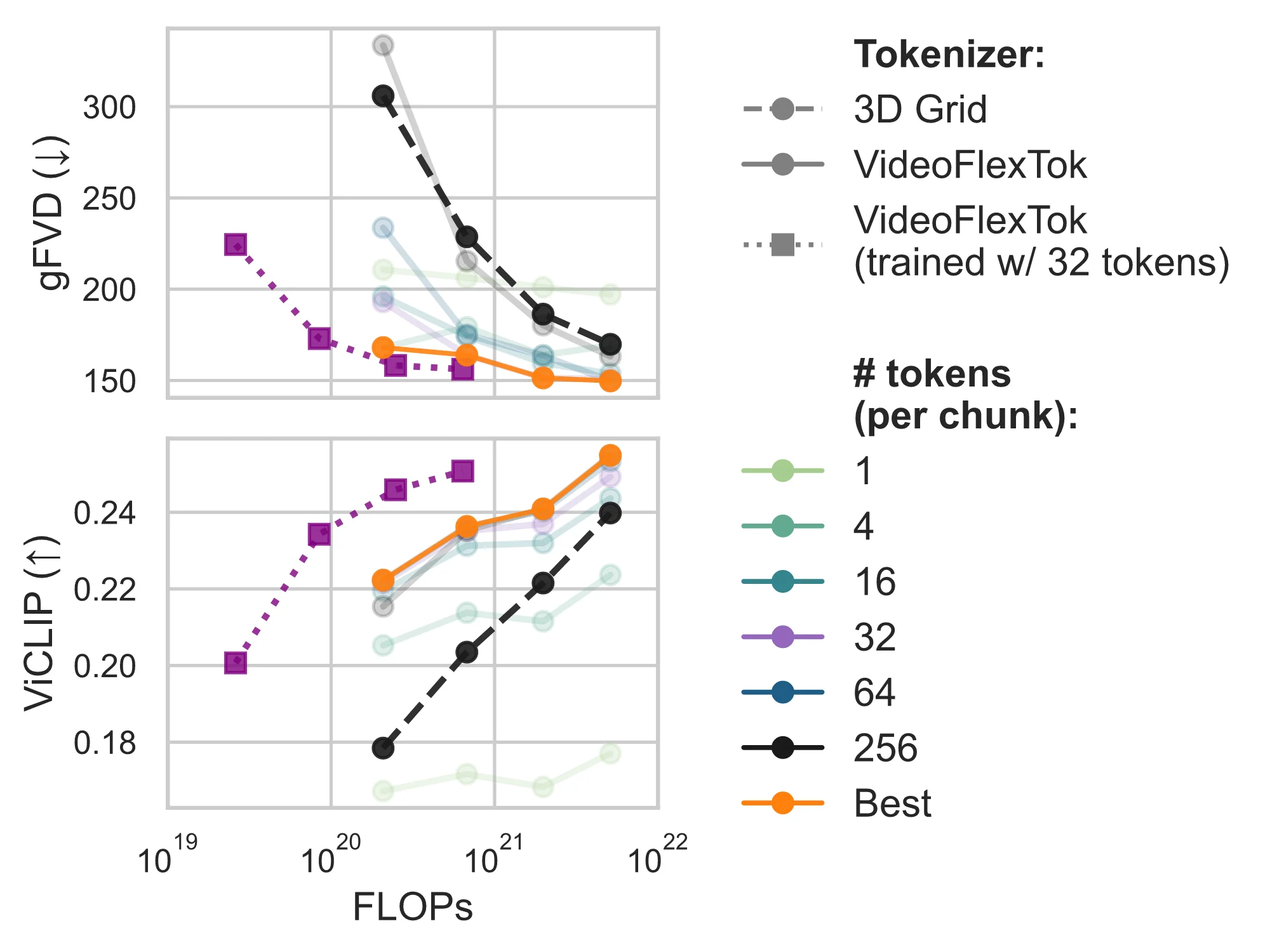
VideoFlexTok training
For implementation, we mainly follow FlexTok and extend it to temporal video data. Our architecture consists of the following three main components:- Time-Causal Encoder is a ViT transformer with register tokens that maps input 3D VAE latent frames $T \times H \times W$ to a temporal 2D sequence of tokens $T \times K$, where $K$ corresponds to the coarse-to-fine ordered tokens, $T$ is the number of latent frames (after temporal compression in VAE). Different from a fully 1D sequence as in LARP, our encoder uses the time-causal attention pattern preserving the temporal structure of the original signal, which we found to be beneficial for downstream video modeling, as well as enabling streaming tokenization. Since our main downstream application is video generation via a GPT-like autoregressive transformer, we also apply FSQ quantization to register tokens.
- Nested dropout randomly drops last $k < K$ register tokens during training, promoting the model to learn an ordered representation where earlier tokens capture most important information and later tokens provide finer details. This is the key component that enables flexible-length coarse-to-fine tokenization.
- Time-Causal Decoder is a DiT-based conditional generative flow model. Given the masked token sequence after nested dropout and noised VAE latents, it reconstructs the clean VAE latents. Reconstruction-based objectives, however, tend to prioritize low-level details, which can prevent earlier tokens in the hierarchy from mainly focusing on semantically meaningful information. We, therefore, use a semantic bias in the form of the REPA loss, found to be useful in FlexTok. Specifically, we train a shallow readout network that predicts DINOv2 features. Finally, we opt for time-causal attention pattern in the decoder which we found to improve the downstream generative modeling performance especially when using fewer tokens.
We train two main VideoFlexTok versions. VideoFlexTok-K600 is a 570M parameter model (excluding adaLN parameters) with an 18-layer encoder and decoder trained on the Kinetics-600 dataset at a 17-frames 128x128 resolution for 400B VAE tokens. VideoFlexTok-Panda is a 1.3B parameter model (excluding adaLN parameters) with an 18-layer encoder and 28-layer decoder trained on a subset of the Panda70M dataset at a 17-frames 256x256 resolution for 400B VAE tokens. We use the codebook size of 64000 for both models.
For VideoFlexTok-Panda, we introduce an additional training stage where we fix the encoder and fine-tune the decoder for another 400B tokens with the following two interventions. First, we switch from time-causal to full attention pattern in the decoder, which leads to better reconstruction quality, especially improving temporal consistency. Note that the encoder remains fixed during this stage, so it retains the benefits from being trained with the time-causal decoder. Second, we introduce a frame-conditioning capability by randomly providing a clean first frame instead of a noised one. This enables streaming tokenization by conditioning the decoder on its previously reconstructed frames during inference. We demonstrate results using this tokenizer version unless stated otherwise.
VideoFlexTok reconstruction visualization
The following visualizations demonstrate the flexible-length tokenization capability of VideoFlexTok. First, we see that no matter the number of tokens used, the reconstructions remain plausible and realistic, thanks to the generative flow decoder. Second, and most interestingly, we find that the first few tokens capture semantically-meaningful information, such as object type, their motion, and overall scene geometry, while abstracting away more nuanced details such as color information, texture, etc. Later tokens progressively add finer details, enabling high-fidelity reconstruction when using more tokens. In the car example, note how the car object type and its rotational motion are well-preserved with as few as 1-4 tokens per frame, while the color and finer details are only reconstructed when using more tokens.